ELFK-实时抓取HAPROXY日志
1、前言
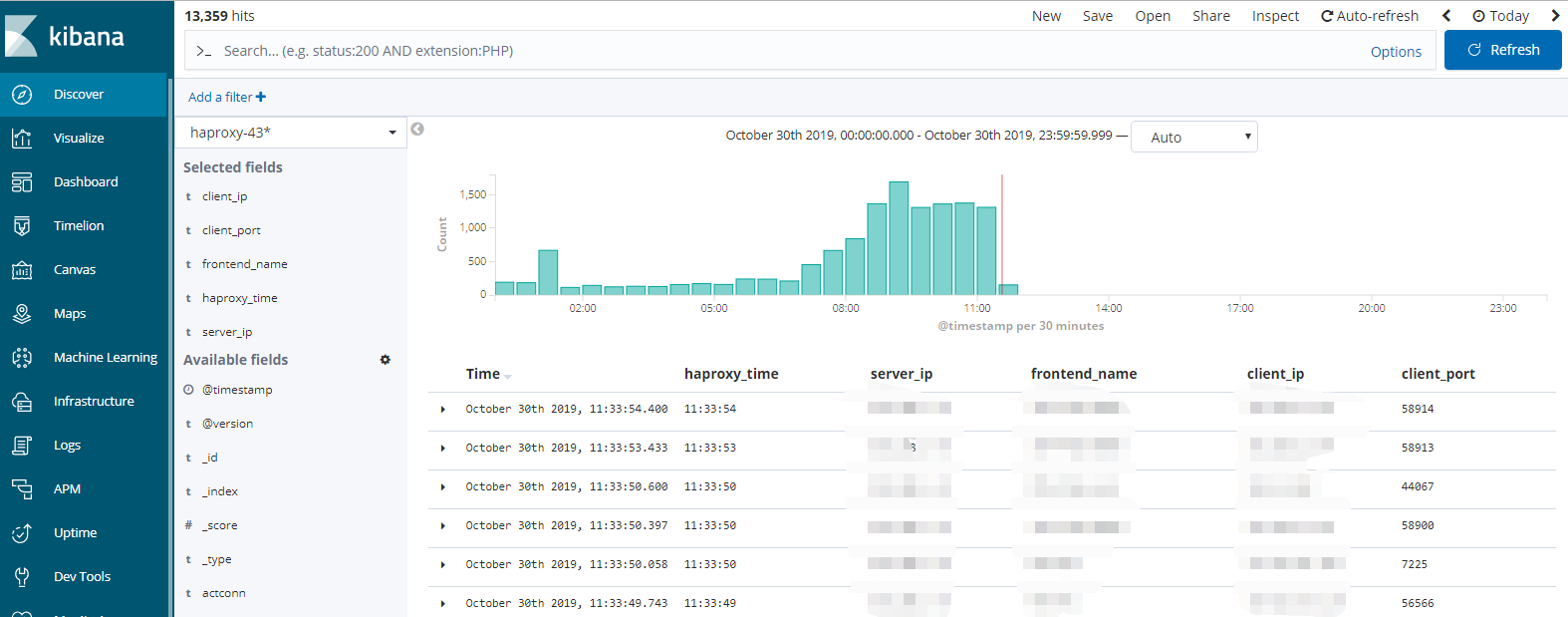
本篇博客仅记录haproxy日志,通过logstash正则进行数据结构化,输出到elasticsearch中,最后通过kibaka进行展示的完整过程,EK的安装及配置方法,请参考:ELK-Stack简介及安装手册
1.1、Logstash简介
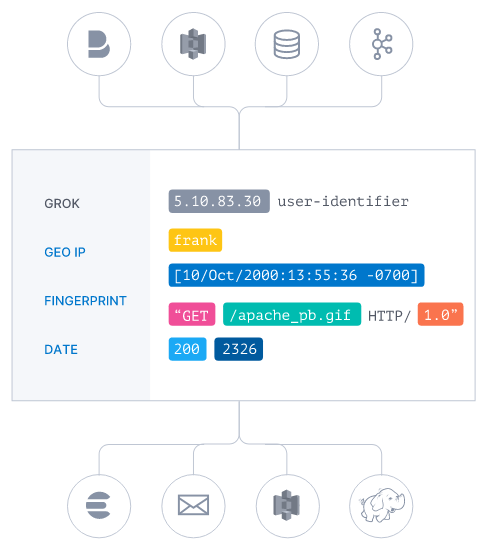
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持 各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。如下图:
- 图一:
2、部署环境介绍
| 平台 | IP | 用途 | E版本 | L版本 | K版本 |
|---|---|---|---|---|---|
| CentOS 6.7 64Bit | 192.168.1.241 | ES+Cerebro+Kibana | 6.7.0 | 6.7.0 | |
| CentOS 6.7 64Bit | 192.168.1.43 | Logstash | 6.7.0 |
2、Logstash的安装与配置
2.1、配置EPEL源+K源(all_logstash)
1 | [root@localhost ~]# rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/Packages/e/epel-release-6-8.noarch.rpm |
2.2、安装JDK及配置系统环境(all_logstash)
1 | [root@test1 ~]# echo "* - nofile 65536" >> /etc/security/limits.conf |
2.3、Logstash安装(all_logstash)
1 | [root@test1 ~]# yum install logstash-6.7.0 |
2.4、导入haproxy_patterns规则库
此规则库来自官方GITHUB,详见:ELK_GROK学习笔记
1 | [root@atmpos patterns]# pwd |
2.5、导入haproxy.conf配置文件
提示:首先根据你HAPROXY的使用类型,来引用对应规则库,目前官方规则库支持httplog、tcplog日志格式
1 | [root@atmpos conf.d]# pwd |
2.6、重启logstash
提示:日志如无ERROR级别的日志,表示数据已开始向ES导入
2
[root@atmpos logstash]# tail -f /var/log/logstash/logstash-plain.log
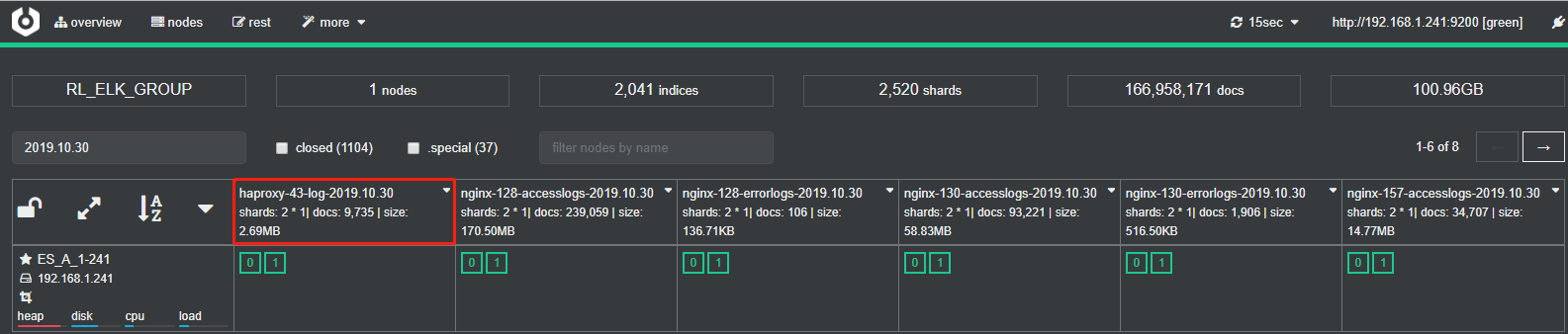
2.7、登录Cerebro查看ES索引及数据情况
ES管理工具下载地址,需JDK1.8环境:https://github.com/lmenezes/cerebro
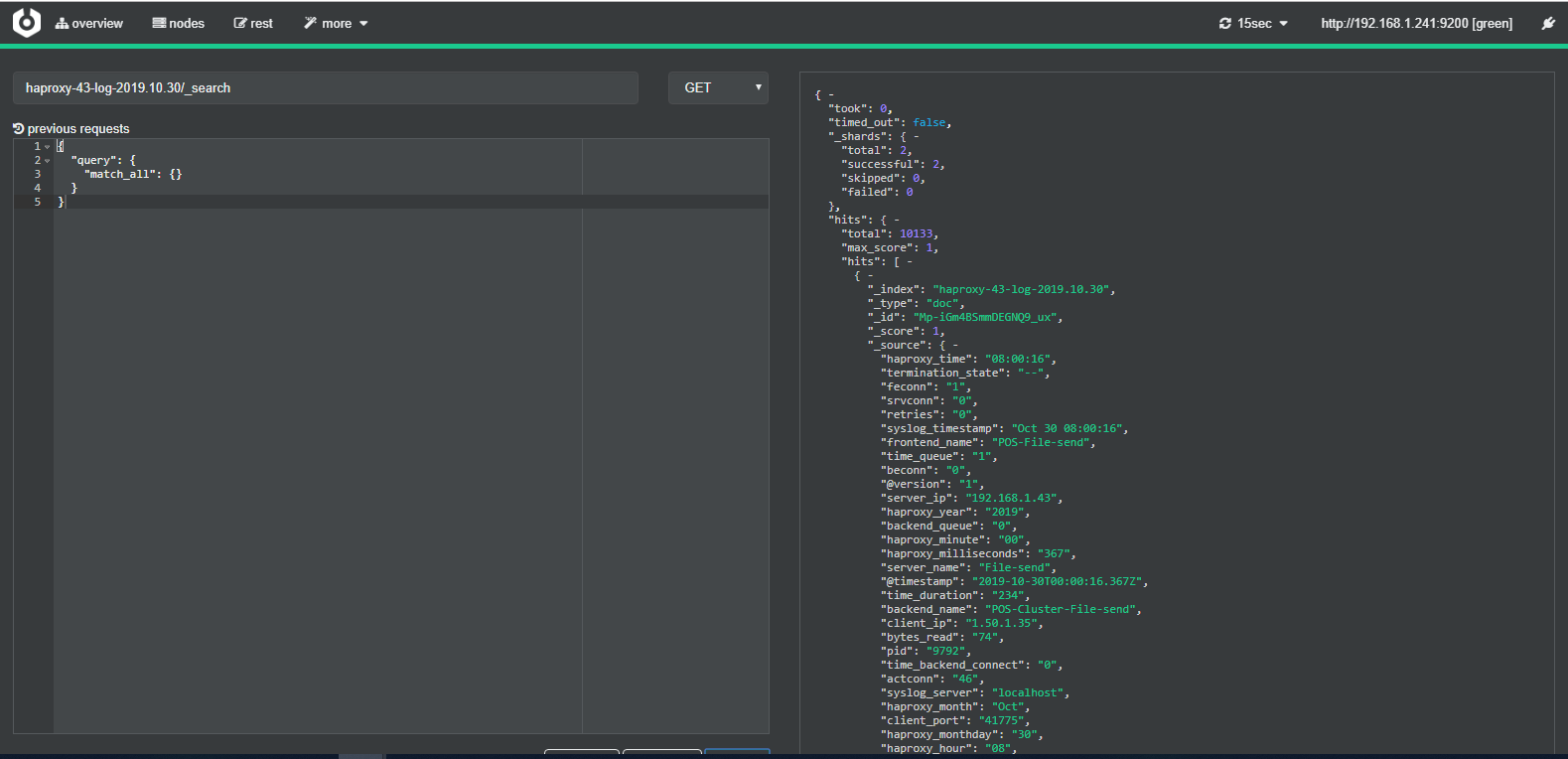
2.8、登录kibana查看ES索引及数据情况