ECK-从Kafka实时抓取JAVA日志
1、前言
本篇博客完整的记录了zk及kafka完整安装过程,并协同开发将java应用日志,直接输出至kafka集群,随后通过logstash的kafka input插件进行主题消费,并通过正则进行数据结构化,最后输出到es集群(es集群通过k8s采用eck模式进行安装),数据结果则使用kibaka进行展示,默认关闭selinux及防火墙,系统优化已提前做完;
2、部署环境介绍
| 平台 | IP | 主机名 | ECK版本 | ZK版本 | Kafka版本 | |
|---|---|---|---|---|---|---|
| CentOS Linux release 7.7.1908 | 192.168.6.10 | DEVOPSSRV01 | ELK:7.10.1 | 3.6.2 | 2.5.0 | |
| CentOS Linux release 7.7.1908 | 192.168.6.39 | DBSRV01 | ELK:7.10.1 | 3.6.2 | 2.5.0 | |
| CentOS Linux release 7.7.1908 | 192.168.6.45 | TSSRV02 | ELK:7.10.1 | 3.6.2 | 2.5.0 |
3、ZooKeeper集群安装与配置
3.1、安装并配置JDK1.8环境
1 | #安装jdk1.8.0_261 |
3.2、下载并安装zk(免编译)
zk下载地址:Apache ZooKeeper™ Releases
1 | #解压二进制安装文件至/usr/local |
3.3、zk集群配置
提示:默认情况下只需要对dataDir进行配置,新增集群配置信息即可;
1 | [root@DEVOPSSRV01 ~]# cd /usr/local/zk-3.6.2/conf/ |
- 附录:zoo.cfg配置文件详解
1 | # 通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。 它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime) |
3.4、zk集群同步
提示:以上操作全部在三台服务器上进行,可使用scp进行快速多机拷贝,拷贝完成后,对
myid进行修改,确保与zoo.cfg中server.x保持一直,并唯一;
1 | #DEVOPSSRV01主机的myid:0 |
3.5、zk集群管理
提示:配置jdk环境变量的时候,已经将zk和kafka的安装目录添加到了path中,可直接使用命令进行管理;
3.5.1、启动集群
1 | #三台机器共同执行zkServer.sh start |
3.5.2、查看集群状态
1 | #三台机器共同执行zkServer.sh status |
- 集群状态:

3.5.3、停止与重启指令
1 | #停止 |
4、Kafka集群安装与配置
提示:安装kafka集群前,确保已安装jdk1.8和zk集群,并配置好相关环境变量,请看第三章节;
4.1、下载并安装kafka(免编译)
kafka下载地址:DOWNLOAD KAFKA
1 | #解压至指定目录 |
4.2、kafka集群配置
1 | #切换至kafka配置文件目录 |
- 附录:broker的配置文件
server.properties详解1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87############################# Server Basics #############################
#每一个broker在集群中的唯一标示,要求是正数
broker.id=0
############################# Socket Server Settings #############################
#服务端监听地址,可采用0.0.0.0,但如果服务器上部署了docker集群,建议绑定固定网卡IP
listeners=PLAINTEXT://192.168.6.10:9092
#处理网络请求的线程数量,也就是接收消息的线程数。
#接收线程会将接收到的消息放到内存中,然后再从内存中写入磁盘
num.network.threads=3
#消息从内存中写入磁盘是时候使用的线程数量。
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
############################# Log Basics #############################
#kafka运行日志存放的路径
log.dirs=/var/log/kafka
#topic在当前broker上的分片个数
num.partitions=1
#我们知道segment文件默认会被保留7天的时间,超时的话就
#会被清理,那么清理这件事情就需要有一些线程来做。这里就是
#用来设置恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
#上面我们说过接收线程会将接收到的消息放到内存中,然后再从内存
#写到磁盘上,那么什么时候将消息从内存中写入磁盘,就有一个
#时间限制(时间阈值)和一个数量限制(数量阈值),这里设置的是
#数量阈值,下一个参数设置的则是时间阈值。
#partion buffer中,消息的条数达到阈值,将触发flush到磁盘。
#log.flush.interval.messages=10000
#消息buffer的时间,达到阈值,将触发将消息从内存flush到磁盘,
#单位是毫秒。
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
#segment文件保留的最长时间,默认保留7天(168小时),
#超时将被删除,也就是说7天之前的数据将被清理掉。
log.retention.hours=720
#topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes 。-1没有大小限制
#log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
#log.retention.bytes=1073741824
#日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
#上面的参数设置了每一个segment文件的大小是1G,那么
#就需要有一个东西去定期检查segment文件有没有达到1G,
#多长时间去检查一次,就需要设置一个周期性检查文件大小
#的时间(单位是毫秒)
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
#zookeeper集群的地址,可以是多个,多个之间用逗号分割
#hostname1:port1,hostname2:port2,hostname3:port3
zookeeper.connect=192.168.6.10:2181,192.168.6.39:2181,192.168.6.45:2181
#zookeeper链接超时时间
#单位是毫秒。
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
#当Consumer Group新增或减少Consumer时,重新分配Topic Partition的延迟时间
group.initial.rebalance.delay.ms=0
4.2、kafka集群同步
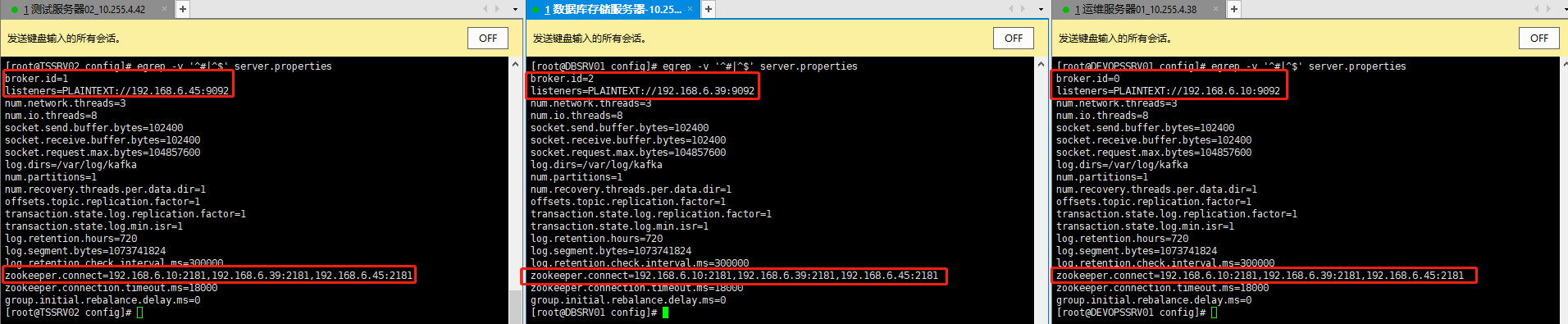
提示:以上操作全部在三台服务器上进行,可使用scp进行快速多机拷贝,拷贝完成后,对
broker.id、listeners、log.dirs、zookeeper.connect关键参数进行修改;
1 | #修改完成后切换至配置文件目录 |
- 配置文件比对:
4.3、kafka集群管理
提示:配置jdk环境变量的时候,已经将zk和kafka的安装目录添加到了path中,可直接使用命令进行管理,
启动kafka集群前必须先确保zk服务正常;
1 | #非交互式启动集群 |
5、Logstash的安装与配置
本篇仅记录抓取java日志的全过程,Logstash的安装请参考:ELFK-实时抓取HAPROXY日志
5.1、java样本数据分析与正则编写
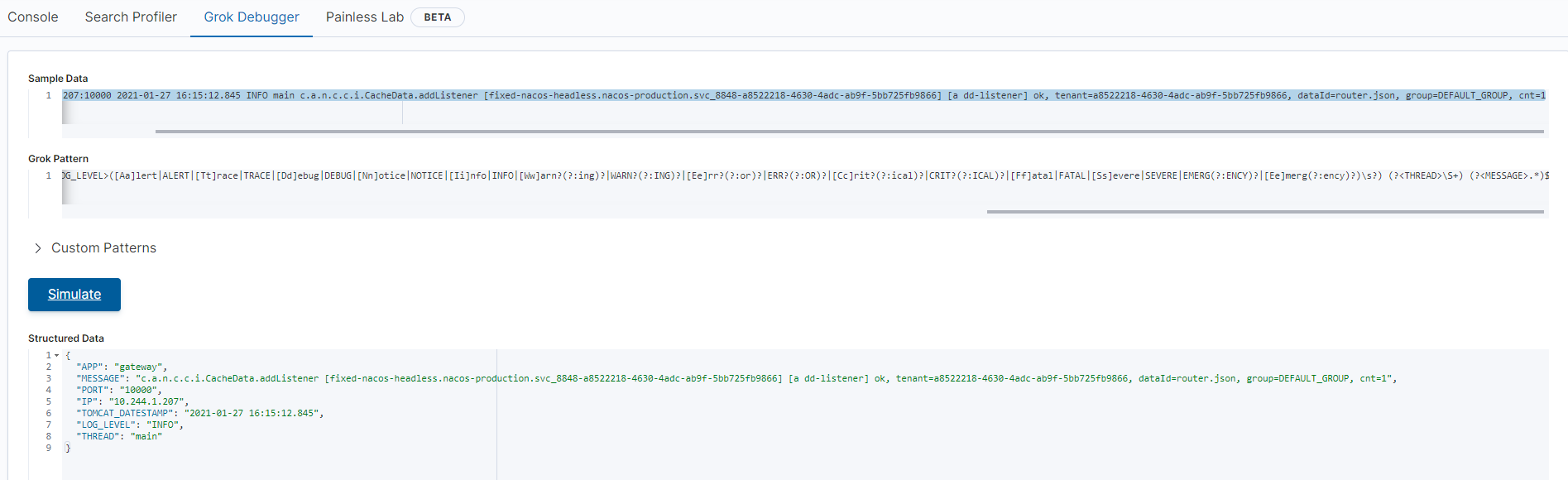
样本数据:
1
gateway:10.244.1.207:10000 2021-01-27 16:15:12.845 INFO main c.a.n.c.c.i.CacheData.addListener [fixed-nacos-headless.nacos-production.svc_8848-a8522218-4630-4adc-ab9f-5bb725fb9866] [a dd-listener] ok, tenant=a8522218-4630-4adc-ab9f-5bb725fb9866, dataId=router.json, group=DEFAULT_GROUP, cnt=1
正则分拆:
1
2
3
4
5
6APP [a-zA-Z]+-?[a-zA-Z]+
IP (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
PORT \b(?:[1-9][0-9]*)\b
TOMCAT_DATESTAMP 20(?>\d\d){1,2}-(?:0?[1-9]|1[0-2])-(?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) (?:2[0123]|[01]?[0-9]):?(?:[0-5][0-9])(?::?(?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?))
LOG_LEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)\s?
THREAD \S+Kibana Grok Debug:
Simulate后,如无报错则表示规则生效,数据结构化详情见
Structured Data一栏
5.2、导入java_patterns规则库
1 | [root@DEVOPSSRV01 logstash]# cd /usr/share/logstash/patterns/ |
5.3、导入java_log.conf配置文件
1 | [root@DEVOPSSRV01 conf.d]# pwd |
5.4、重启logstash
提示:日志如无ERROR级别的日志,表示数据已开始向ES导入,随后请登录kibana查看数据情况
1 | [root@DEVOPSSRV01 logstash]# systemctl restart logstash.serivce |
5.5、登录kibana创建索引查看数据
输入es用户名和密码
创建索引
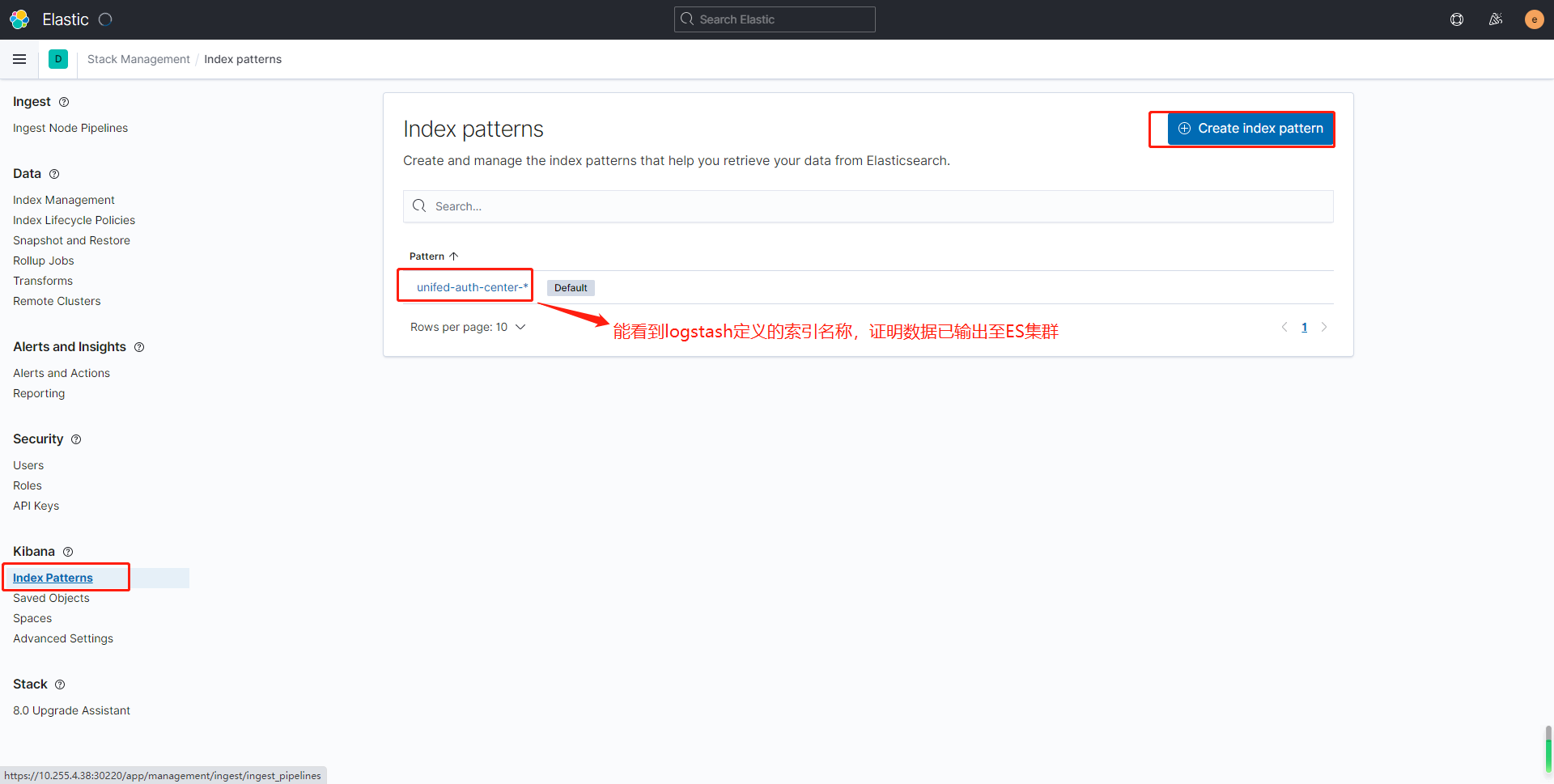
返回首页,打开Discover查看数据
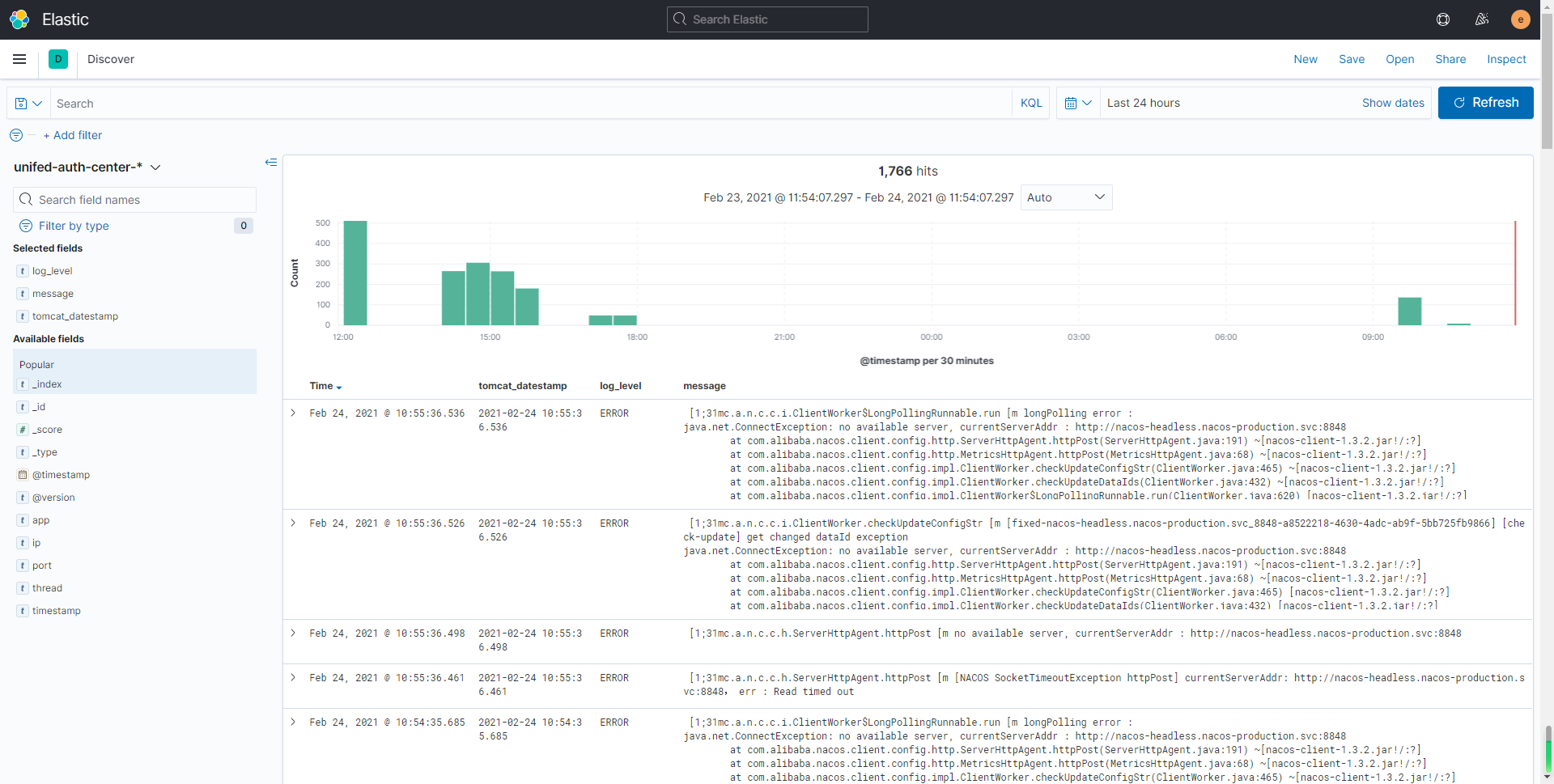
6、其他资料
- 阿里资料:消息队列Kafka版可以作为Input接入Logstash
- Logstash Reference:官方logstash资料